
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- 네이버매물크롤링
- venv 설치
- selenium
- 네이버커머스API
- uipath 입문
- pycdas.exe
- pywinauto 윈도우제어
- pywinauto 윈도우
- UiPath
- 날짜 정규식
- Uipath 설치방법
- vscode venv 설치
- 가상환경설치
- pywinauto
- 파이썬네이버부동산
- 네이버 로그인 영수증 해결
- Element is not clickable at point
- 파이썬 환경설정
- 네이버부동산크롤링
- 파이썬 네이버 로그인
- 파이썬 가상환경 설치
- pycdc.exe
- Uipath 기초
- 왕초보 파이썬 실행
- 네이버 로그인 캡챠해결
- 네이버 로그인 하기
- 커머스API
- Selenium 셀렉터잡기
- Python
- 파이썬 가상환경 설치방법
- Today
- Total
목록전체 글 (384)
콘솔워크
def close_popups(self): driver = self.driver tabs = driver.window_handles print(tabs) try: while len(tabs) != 1: tabs = driver.window_handles print(tabs) driver.switch_to.window(tabs[1]) driver.close() except Exception as e: print('no popups') finally: driver.switch_to.window(tabs[0]) 활성화 된 창이 1개가 될때까지 새 창을 닫는다.
 파이썬 셀레니움 특정 텍스트가 포함된 태그 바로 옆 태그의 text 가져오기
파이썬 셀레니움 특정 텍스트가 포함된 태그 바로 옆 태그의 text 가져오기
code = driver.find_element(By.XPATH, f'//td[contains(text(), "인증번호")]/following-sibling::td').text 네이버 메일에서 인증번호를 가져와야 하는 일이 생겼다. 특정 텍스트는 "인증번호"라는 글자이고 그 바로옆에 6자리 숫자코드가 필요했다. 원리는 다음과 같다. driver.find_element(By.XPATH, f'//td[contains(text(), "인증번호")]/following-sibling::td').text driver.find_element(By.XPATH, f'//태그명[contains(text(), "포함텍스트")]/following-sibling::타겟태그명').text Xpath 기준으로 가져오는 코드는 다음..
from selenium.webdriver.common.by import By from selenium.webdriver.support.ui import WebDriverWait from selenium.webdriver.support import expected_conditions as EC WebDriverWait(driver, 30).until(EC.presence_of_element_located((By.CSS_SELECTOR, '#your_element'))) 한줄로 끝내기
# 칼럼1에 '단어1'이 포함 된 데이터 필터링 new_df1 = df.loc[df['칼럼1'].str.contains('단어1')] # 칼럼1에 '단어1'이 포함 되지 않은 데이터 필터링 new_df2 = df.loc[~df['칼럼1'].str.contains('단어1')] # or 연산자 사용 가능 new_df3 = df.loc[df['칼럼1'].str.contains('단어1|단어2')]
element = driver.find_element(By.XPATH, f"//td[contains(.,'{your_text}')]") 참고 문서: https://qa.wujigu.com/qa/?qa=760508/python-selenium-syntaxerror-failed-execute-evaluate-document-the-string-div-contains-%40class-product-card__subtitle
숫자 나누기 print(7/9) >>>>>> 0.7777777777777778 나눈 나머지 구하기 print(7%9) >>>>>> 7 둘 다 구하는 함수 result = divmod(7, 9) print(result) print(result[0]) print(result[1]) >>>>>>>>>>>> (0, 7) 0 7
Dog Cat Hamster Parrot Spider Goldfish from selenium.webdriver.support.select import Select select = Select(driver.find_element(By.NAME, 'pets')) select.select_by_index(1) select.select_by_visible_text('Cat') select.select_by_value('hamster')
import shutil from selenium.webdriver.common.by import By # 폴더내 파일 전체 삭제 def delete_all_files(self, download_path): if os.path.exists(download_path): for file in os.scandir(download_path): os.remove(file.path) return 'Remove All File' else: return 'Directory Not Found' # 경로의 파일 갯수 체크 def dir_search(self, download_path): file_len = len(os.listdir(download_path)) print('파일갯수: ' + str(file_len)) re..
파이썬은 추상 클래스(abstract class)라는 기능을 제공합니다. 추상 클래스는 메서드의 목록만 가진 클래스이며 상속받는 클래스에서 메서드 구현을 강제하기 위해 사용합니다. 먼저 추상 클래스를 만들려면 import로 abc 모듈을 가져와야 합니다( abc는 abstract base class의 약자입니다). 그리고 클래스의 ( )(괄호) 안에 metaclass=ABCMeta를 지정하고, 메서드를 만들 때 위에 @abstractmethod를 붙여서 추상 메서드로 지정합니다. from abc import * class 추상클래스이름(metaclass=ABCMeta): @abstractmethod def 메서드이름(self): 코드 여기서는 from abc import *로 abc 모듈의 모든 클래스와..
간혹 엑셀파일에서 숫자로 된 문자열을 읽어오면 뒤에 소수점이 붙어버리는 경우가 있다. ex) 3000.0 이런 경우 강제로 형변환을 하게되면 위와 같은 오류가 발생하는데 그런 경우 사용할 수 있다. def filter_only_digit_remove_dot(text): text = str(text) if text.find(".") > -1: text = text.split(".")[0] numbers = re.findall(r'\d+', text) return ''.join(numbers)
이미지 파일 경로가 적혀있는 list에서 파일을 검증해보고 없으면 제외해야 할 때 만들었다. 딱히 이미지가 아니어도 경로만 잘 입력되어있으면 상관없음. # 실제 폴더에 파일이 없으면 목록에서 제외 def verify_imgs(self, img_list): for img in img_list[:]: if os.path.isfile(img) == True: pass else: img_list.remove(img) print(img_list) return img_list
 [pyqt5] 로그창이 있는 기본적인 형태의 GUI
[pyqt5] 로그창이 있는 기본적인 형태의 GUI
pip install pyqt5 설치 필요 from tkinter import * # __all__ import sys from tracemalloc import start import warnings warnings.simplefilter("ignore", UserWarning) sys.coinit_flags = 2 from tkinter import HORIZONTAL, Button, Scrollbar from PyQt5.QtGui import * from PyQt5.QtWidgets import * from PyQt5.QtCore import * from datetime import * class MainUI(QWidget): def __init__(self): super().__init__() s..
import pandas as pd from openpyxl import * import time class Bot(): def __init__(self): self.default_wait = 10 print(f'ready') def work_start(self, excel_path): book_df = pd.read_excel(excel_path, '특정거래처 판매현황', keep_default_na=False) print(len(book_df)) book_code_list = [] for book_df_len in range(len(book_df)): book_code = book_df.iloc[book_df_len].도서코드 book_code_list.append(book_code) # 배열 중복제..
import os import random import numpy as np import cv2 def image_convert_random(inpath, outpath): img = cv2.imread(inpath) random_color = list(np.random.choice(range(256), size=3)) print(random_color) for x in range(0, img.shape[1]): for y in range(0, 20): img[y, x] = (random_color) img = img random_value = random.randrange(1, 41) print(random_value) mask = np.ones_like(img) * random_value light_..
my_date = '2022-07-07' my_date = datetime.strptime(my_date, f'%Y-%m-%d').date() print(my_date) print(type(my_date)) 자주쓰는 날짜 포맷 코드 %d
가끔 괄호안에 날짜를 입력해놓은 파일들이 있고 그걸 추출해야하는 경우가 있는데 그 때 사용할 수 있다. import re my_date = None file_names = f'발주정보(123)(2022-07-07)(test)(괄호안문자)(ㅁㄴㅇㄹ)-거래처코드임시변경.xlsx' # 괄호안에 들어있는 문자들을 추출해 리스트에 담는다 # 출력결과: ['123', '2022-07-07', 'test', '괄호안문자', 'ㅁㄴㅇㄹ'] bracket_pattern = r'\(([^)]+)' file_names = re.findall(bracket_pattern, file_names) print(f'{file_names}') # 위의 출력결과에서 날짜에 해당하는 문자를 선택한다. # yyyy-MM-dd 형식의 숫자를..
download_path = r'C:\excels' file_name = download_path + "\\" + r"df.xlsx" order_list = [] # 폴더가 있는지 확인 후 없다면 폴더 생성 if os.path.isdir(download_path) == False: os.mkdir(download_path) else: print(f'이미 폴더가 있습니다.') # 파일이 있는지 확인 후 없다면 파일 생성 # 열 정보만 갖고있는 엑셀파일을 생성하는 예시 if os.path.isfile(file_name) == False: save_df = pd.DataFrame(order_list, columns=['열1']) save_df.to_excel(file_name, index=False) else..
download_path = r'C:\excels' new_file_name = max([download_path + "\\" + f for f in os.listdir(download_path)],key=os.path.getctime) shutil.move(new_file_name,os.path.join(download_path,r"your_file.xlsx")) new_file_name = download_path + "\\" + r"your_file.xlsx" print(f'{new_file_name}') 해당 폴더의 파일 중 수정일자가 가장 최근인 파일의 이름을 바꿀 수 있다.
외부 사이트에서 크롤링한 문자열에 이모지가 포함되어있는데 그걸 클립보드에 복사하고 크롬에 붙여넣으면 오류가 발생하는 경우가 있다. 문자열에서 해당 이모지를 지워주는것으로 해결이 가능하다. pip install emoji 를 먼저 실행 할 것 import emoji # 문자열 이모지 제거 def remove_emoji(content): content = emoji.get_emoji_regexp().sub(u'', content) return content
def run_papago(driver, content): translate_content = '' # 새 탭 열기 driver.execute_script('window.open();') time.sleep(1) # 좌측 한국어 설정 우측 일본어 설정 https://papago.naver.com/?sk=ko&tk=ja&hn=0 driver.switch_to.window(driver.window_handles[-1]) driver.get(f'https://papago.naver.com/?sk=ko&tk=ja&hn=0') time.sleep(1) # 번역 작업 try: # 좌측에 문자열 입력 source_textarea = driver.find_element(By.CSS_SELECTOR, 'textarea#..
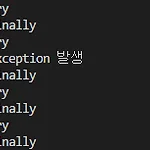 공통 언어 try except finally continue return
공통 언어 try except finally continue return
for i in range(1, 5): try: print('try') raise Exception('123') except: print('exception 발생') continue finally: print('finally') try catch finally 시 continue 만나면 finally 구문에 도달하나요? 네 도달 합니다. finally 구문은 항상 만남. try * 정상이라면 이 코드는 아무런 문제없이 블록의 시작부터 끝까지 실행된다. * 하지만 경우에 따라 예외가 발생할 수 있다. * 예외는 throw 문에 의해 직접적으로 발생할 수도 있고, * 또는 예외를 발생시키는 메서드의 호출에 의해 발생할 수도 있다. catch * 이 블록 내부의 문장들은 오직 try 블록에서 예외가 발생할 경..
selenium으로 크롤링을 하다보면 간혹 스크롤을 내릴때마다 자료가 추가되는 사이트가 있는데, 그 때 유용하게 쓰일 스크롤을 내리는 함수이다. def repeat_scroll(self, driver): #스크롤 내리기 전 위치 scroll_location = driver.execute_script("return document.body.scrollHeight") while True: #현재 스크롤의 가장 아래로 내림 driver.execute_script("window.scrollTo(0,document.body.scrollHeight)") #전체 스크롤이 늘어날 때까지 대기 time.sleep(2) #늘어난 스크롤 높이 scroll_height = driver.execute_script("return..
컬럼A의 길이가 10인 데이터 추출 map. lamda 이용 df = df[df['A'].map(lambda x: len(str(x)) == 10)]
 크롬 개발자도구로 지마켓의 기간검색 범위 바꿔보기
크롬 개발자도구로 지마켓의 기간검색 범위 바꿔보기
어느 날 지마켓에서 지금까지 주문했던 주문내역들을 조회를 해보려고 하는데, 기간검색을 시도하니 1개월, 보름, 일주일 단위로밖에 작동하지 않는 것을 보았다. 너무나도 불편한 사이트 설정이었기에 크롬의 개발자도구 (F12)로 달력을 살짝 살펴보았다. 위 구조를 살펴보면 각종 값을 입력받을 수 있는 태그지만 readonly="true"라는 부분때문에 키보드입력으로 편집하는 것이 막힌 것을 확인할 수 있었다. value라는 부분이 실제로 반영되는 기간을 나타낸 것 같았다. 저 부분을 수정한다면 1일 단위로도 기간검색이 가능하지 않을까 생각하여 바로 개발자도구로 시도해보았다. 바로 몇 줄 써내려가 보았다. document.querySelector('#searchSDT').readOnly = false docum..
 [selenium] selenium으로 네이버 로그인 시 영수증 인증화면이 뜨는 경우
[selenium] selenium으로 네이버 로그인 시 영수증 인증화면이 뜨는 경우
다른 사이트에서 하듯이 selenium으로 네이버에 로그인을 시도하려고 하면 아래와 같은 영수증 화면이 뜨게 된다. 아마 네이버쪽에서 기계적인 움직임이나 외부 코드가 개입하는 것을 인식하여 인증화면이 발생하는 것 같다. 현재로써는 영수증 인증을 뚫을 방법이 생각나지 않아서, 아예 영수증 화면을 회피하는 방법, 즉 최대한 사람과 같은 움직임으로 로그인을 시도했더니 로그인에 성공하게 되었다. 영수증 인증화면이 발생하던 코드 # 영수증 인증화면이 발생하는 코드 def login(self, id, pw): driver = get_chrome_driver_new(is_scret=True, is_headless=False) driver.maximize_window() driver.get('https://nid.na..
내가 원하는 내용이 다소 복잡하여 글로 정리한다. dataframe 두개가 있다. 각각 df1 그리고 df2라고 지칭하겠다. 일단 먼저 특정 컬럼을 기준으로 LEFT JOIN 하는 코드는 다음과 같다. KEY 컬럼 ('묶음번호', '주문번호', '구매자') DATAFRAME LEFT OUTER JOIN 예시 KEYS = ['묶음번호', '주문번호', '구매자'] SUFFIX = '_DROP' df1 = df1.fillna('') df2 = df2.fillna('') merge_df = pd.merge(df1, df2, how='left', on=KEYS, suffixes=('', SUFFIX)) - SUFFIX의 값은 두번째 DF에 붙는 접미사이다. 특정 컬럼의 값이 빈값인 경우 뒤의 데이터컬럼의 값으로..
가끔 selenium으로 url을 긁어오는데 한글로 되어있는 부분이 특수문자로 바뀌어있는 경우가 있다. ex) https://www.asdfasdfasdf%#$#$@#@#!#@$#$ 이는 urllib 패키지의 urllib.parse.unquote 모듈을 사용하면 정상적인 문자열로 출력할 수 있다. import urllib url = 'https://www.asdfasdfasdf%#$#$@#@#!#@$#$' def encode_url(url): encode_url = urllib.parse.unquote(url) print(encode_url) return encode_url
selenium으로 webelement를 찾다보면 가끔 webelement의 부모를 찾아야 하는 경우가 있다. javascript의 .parentElement를 사용해도 해결이 가능하지만 가능하면 파이썬과 셀레니움 코드만으로 해결을 하고싶을 때가 있는데 아래의 코드처럼 XPATH를 이용하면 된다. your_button = driver.find_elements(By.CSS_SELECTOR, '#your_button') # 부모 element를 찾기위한 코드 parent_el = your_button.find_element(By.XPATH, '..') # 부모의 부모 element도 찾을 수 있다 grand_el = parent_el.find_element(By.XPATH, '..')
딕셔너리 내부의 모든 string key를 int로 변경하는 함수이다. {'1' : '123', '2' : '1234'} >> {1 : '123', 2: '1234'} def dict_str_key_to_int(target_dict): return {int(k) if k.isnumeric() else k :v for k,v in target_dict.items()}
selenium으로 작업을 하다보면 간혹 요소가 존재하지만 클릭 할 수 없는 오류가 발생한다. 보통 해당 요소로 스크롤을 내려 화면에 보이게하면 해결이 되는 간단한 문제이다. 이런 경우에는 ActionChains.move_to_element() 메소드를 활용하면 간단하게 해결 할 수 있다. 코드 사용예시 from selenium.webdriver.common.action_chains import ActionChains your_el = driver.find_element(By.CSS_SELECTOR, '#your_el') print(have_next) # 해당 요소가 화면에 존재하지 않으면 클릭할 수 없으므로 요소가 보일때까지 스크롤하는 액션 actions = ActionChains(driver).mov..