
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- 파이썬 환경설정
- 파이썬네이버부동산
- selenium
- pywinauto 윈도우제어
- 파이썬 네이버 로그인
- pywinauto
- 날짜 정규식
- 네이버 로그인 캡챠해결
- 가상환경설치
- Uipath 기초
- 네이버 로그인 영수증 해결
- pywinauto 윈도우
- UiPath
- pycdc.exe
- 네이버매물크롤링
- Element is not clickable at point
- 파이썬 가상환경 설치
- 네이버부동산크롤링
- Python
- vscode venv 설치
- Selenium 셀렉터잡기
- pycdas.exe
- 커머스API
- uipath 입문
- 파이썬 가상환경 설치방법
- venv 설치
- 왕초보 파이썬 실행
- Uipath 설치방법
- 네이버 로그인 하기
- 네이버커머스API
- Today
- Total
목록분류 전체보기 (384)
콘솔워크
패키지 설치합니다. pip install openpyxl 특정 엑셀에 B열에 있는 셀서식을 모두 숫자형식으로 바꾸고 싶었습니다. 그래서 아래와 같은 코드가 탄생했습니다. from openpyxl import Workbook, load_workbook from openpyxl.styles import numbers from openpyxl import Workbook excel = r"C:\Users\consolework\Downloads\엑셀합치기결과_20230602163911.xlsx" # Load the workbook workbook = load_workbook(excel) sheet = workbook.active # Change the format of cells from B2 to the en..
패키지 설치합니다. pip install pandas 한 폴더 내의 엑셀들을 하나로 합치는 기능을 담은 class 입니다. import os import pandas as pd from datetime import datetime class ExcelWorkFeature: def __init__(self) -> None: pass # 폴더 내의 엑셀을 합치기 def combine_excel(self, folder_path: str) -> None: # folder_path : 엑셀 파일 경로 print(folder_path) # 폴더 내 모든 엑셀 파일 경로 가져오기 excel_files = [f for f in os.listdir(folder_path) if f.endswith(".xlsx")] exc..
 python selector xpath 크롬 콘솔에서 테스트방법
python selector xpath 크롬 콘솔에서 테스트방법
파이썬으로 웹자동화를 구현할 때 vscode나 파이참에서 직접 실행하고 디버그 해봐야지만 그 동작이 되는지 파악하시나요? 그러면 개발시간이 오래걸립니다. 보통 CSS_SELECTOR 기반으로 셀렉터 잡을때는 크롬 브라우저 콘솔창에서 document.querySelector 이용해서 찾습니다. 하지만 태그에 포함되어있는 텍스트 기반 찾을 때는 xpath를 사용하면 편리한데요. 문제는 xpath를 크롬에서 직접 디버그 할 수 있지 않을까 찾던중 방법을 알아냈습니다. 방법은 $x() 함수를 사용하면됩니다. $x('//div[@class="row"][.//label[text()="검색수"]]//input') $x('//td[contains(@class, "PagerTotal")]/div') $x('//input..
beautifulsoup4 라이브러리를 설치한다. pip install beautifulsoup4 from bs4 import BeautifulSoup html_file = r"__test__\article_sample.html" page = open(html_file, "rt", encoding="utf-8").read() # HTML 파일 읽고 문자열 리턴 soup = BeautifulSoup(page, "html.parser") # Soup 객체 생성 # div와 p 두 종류가 있음 for div in soup.find_all(["div", "p"]): print(div) beautifulsoup4 라이브러리를 사용하면 html을 쉽게 파싱할 수 있다. fild_all 함수를 이용하여 원하는 태그만..
https://extrememanual.net/37073 윈도우10 갑자기 재부팅되는 현상 해결 방법 - 익스트림 매뉴얼 윈도우를 사용하다가 갑자기 재부팅이 되는 경우가 있는데요. https://itons.net/%EC%9C%88%EB%8F%84%EC%9A%B010-%EC%BB%B4%ED%93%A8%ED%84%B0-%EB%B6%80%ED%8C%85-%EC%8B%9C%EA%B0%84-%ED%99%95%EC%9D%B8%ED%95%98%EB%8A%94-%EB%B0%A9%EB%B2%95
 python 날짜 n월 n주차 구하기
python 날짜 n월 n주차 구하기
규칙 1. 주의 시작은 월요일이다. 2. 월~일 까지 중 월이 다른 경우 어느 월을 선택할지 기준은 더 많은 쪽을 선택하면 된다. 3. 따라서, 더 많은 쪽을 나누는 기준은 "목요일"이다. 예를들어, 위의 규칙으로 2023년 5월 30일은 몇주차 일까? 6월 1주차일까 5월 5주차일까? 정답은 6월 1주차이다. 왜냐하면 목요일이 6월달이기 때문이다. from datetime import datetime, date, timedelta import lunardate import calendar import numpy as np last_day_of_month = [31, 28, 31, 30, 31, 30, 31, 31, 30, 31, 30, 31] leap_year_last_day_of_month = [31..
pip install random_user_agent #!/usr/bin/env python if 1 == 1: import sys import os sys.path.append(os.path.dirname(os.path.abspath(os.path.dirname(__file__)))) from random_user_agent.user_agent import UserAgent from random_user_agent.params import SoftwareName, OperatingSystem class RandomUserAgentTest: def __init__(self): self.get_headers() print(self.headers) def set_user_agent(self): softwar..
from enum import Enum class Color(Enum): RED = 1 GREEN = 2 BLUE = 3 my_color = 'RED' color = getattr(Color, my_color) print(color) # Color.RED getattr() 함수를 사용하여 문자열로 표현된 Enum 멤버를 가져오는 방법
사실 파이썬은 interface 를 단어 그 자체로서 존재하고 지원하는 언어는 아닙니다. 다만, https://peps.python.org/pep-3119/ 를 읽어보면 알 수 있듯이 추상 메서드와 같은 인터페이스 비슷한 문법을 제공합니다. python 웹 스크래퍼 작성 중, 필히 구현되어야 하는 메서드들을 한데 묶어두고 관리해야 할 필요성을 느껴 인터페이스를 만들게 되었습니다. ( - 사실 best practice 인지는 모르겠습니다.) from abc import ABC, abstractmethod class BaseScrapper(ABC): """ 모든 스크래퍼의 기본 스크래퍼입니다. 해당 클래스를 상속받는 클래스는 아래의 메서드를 필수로 구현해야 합니다. """ @abstractmethod def..
기본적으로 변경할 때, PyQt5로 되어있는 import만 PySide6로 변경하면 바로 사용이 가능하지만, 몇가지 손을 봐야하는 경우가 있음. # PyQt5 cp = QDesktopWidget().availableGeometry().center() # Pyside6 cp = QGuiApplication.primaryScreen().availableGeometry().center() # PyQt5 @pyqtSlot() # Pyside6 @Slot() # PyQt5 pyqtSignal() # Pyside6 Signal() 시그널 및 슬롯의 구문을 그대로 사용하는 것은 가능하지만, import 해야하는 구문이 달라지기 때문에 그에 맞게 변환해주어야 작동한다. # PyQt5 from PyQt5.QtCore i..
 동작하는 최소한의 chrome extension 만들기
동작하는 최소한의 chrome extension 만들기
https://support.google.com/chrome/a/answer/2714278?hl=ko 맞춤 Chrome 앱 및 확장 프로그램 만들기 및 게시하기 - Chrome Enterprise and Education 고객센터 도움이 되었나요? 어떻게 하면 개선할 수 있을까요? 예아니요 support.google.com 기본적으로 이곳을 참고하면 됩니다. 저의 경우.. 위와 같은 구조로 작성하였고, manifest.json 은 아래와 같습니다. { "manifest_version": 3, "name": "HTML을 뽑아내보자 >_
app = Flask(__name__) app.config['JSON_AS_ASCII'] = False 반환은 이런 식으로~~ data = dict( # whatever you want man.. ) return jsonify(data)
 특정 열의 정보가 같은 행끼리 모아서 새로운 dataframe을 만드는 법
특정 열의 정보가 같은 행끼리 모아서 새로운 dataframe을 만드는 법
import pandas as pd df = pd.DataFrame({'name': ['Alice', 'Bob', 'Charlie', 'David', 'Eva', 'Frank'], 'age': [25, 28, 30, 25, 23, 28], 'city': ['Seoul', 'New York', 'Seoul', 'Paris', 'Seoul', 'New York']}) df_grouped = df.groupby('city').agg(list) print(df_grouped) city열의 정보가 같은 행을 따로 모아서 df_grouped를 새로 만들었다.
def get_df_filtered(self, df_result: pd.DataFrame): query_string = f"(열1 > {변수1}) and (열2 > {변수2}) or (열3 > {변수3}) not (열4 > {변수4})" print(f"query_string: {query_string}") df_filtered = df_result.query(query_string) return df_filtered 비교 연산자, 논리 연산자와 같은 연산자를 변수로 받아와서 사용하는 것도 가능하기 때문에 df.loc[]보다 유용하게 사용할 수 있다.
"배송비 3,000원 ㅣ1개 초과 구매하면 배송비 추가" 와 같은 문자열이 있을 때, "3000" 과 같은 숫자만 뽑아내야 할 일이 있었습니다. re.search("\d+,*\d*", delivery_price).group(), 와 같은 코드를 사용하여 해결했습니다. "연속 숫자" + "쉼표" + "숫자" 를 문자열에서 반환합니다.
chrome_options = Options() chrome_options.add_argument("--headless") driver = webdriver.Chrome(options=chrome_options) 아래와 같이 응용할 수도 있겠습니다. def create_driver(): chrome_options = Options() chrome_options.add_argument("--headless") return webdriver.Chrome(options=chrome_options) #################### # example useage...# #################### driver = create_driver() driver.get("bla bla bla...") # d..
num_list = ['1', '2', '3', '4', '5'] num_sum = sum(map(int, num_list)) print(num_sum) # 출력 결과: 15 빠름
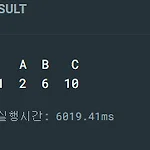 dataframe에서 값이 일치하는 열이 있는 행을 검색하는 코드
dataframe에서 값이 일치하는 열이 있는 행을 검색하는 코드
import pandas as pd # 샘플 데이터프레임 생성 df = pd.DataFrame({'A': [1, 2, 3, 4], 'B': [5, 6, 7, 8], 'C': [9, 10, 11, 12]}) # 값이 일치하는 열이 있는 행 검색 search_value = 2 # 검색할 값 search_column = 'A' # 검색할 열 result = df.loc[df[search_column] == search_value] print(result) 위와 같이 검색을 한다면 A열이 2인 행, 즉 1행을 출력하게 된다.
'//div[@class="row"][.//label[text()="검색수"]]//input' '//td[contains(@class, "PagerTotal")]/div' '//input[contains(@name, "REMARK")]' '//a[contains(@href, "onLogin()")]' f'//tr[./td[contains(text(), "{order_code}")]]/td[contains(@class, "HideCol0C9")]'
def get_download_file(download_folder): extension = ".xlsx" filename = "itemscout_io" excel_files = glob.glob(f"{download_folder}/{filename}*{extension}") print(excel_files) download_file = max([f for f in excel_files], key=os.path.getctime) return download_file
import win32com.client as win32 def xls_to_xlsx(source): if not str(source).find("xls") > -1: return excel = win32.Dispatch("Excel.Application") # excel = win32.gencache.EnsureDispatch("Excel.Application") wb = excel.Workbooks.Open(source) xlsx_file = source + "x" if os.path.isfile(xlsx_file): os.remove(xlsx_file) wb.SaveAs(xlsx_file, FileFormat=51) # FileFormat = 51 is for .xlsx extension wb.Cl..
def get_first_text_in_brackets(text: str): result = "" bracket_pattern = r"\[([^]]+)" result = re.findall(bracket_pattern, text) try: result = result[0] except: pass return result
원래 pyinstaller로 빌드하면 아이콘 (ico) 형식의 이미지만 넣을 수 있다. 하지만 이미지가 너무꺠진다. 이럴 때는 --noupx 옵션을 주어 이미지가 축소되지 않는 것을 넣어준다. 해당 프로젝트에는 Piilow 라이브러리가 설치되어 있어야 한다. pip install Pillow png 형식의 이미지를 넣으려면 아래 형식으로 넣으면 된다. pyinstaller -n "[파일명]" -w --onefile --clean "main.py" --icon "[이미지주소]" --noupx EX) pyinstaller -n "sample file v1.0.0" -w --onefile --clean "main.py" --icon "assets\image.png" --noupx
우선 프로젝트를 몰아넣고 싶은 빈 프로젝트를 하나 생성하고 github에 연결한다. 그 후 연결되어있는 프로젝트 안에서 아래와 같은 명령어 입력 git subtree add --prefix="이름설정" 주소 브런치명 복사하고자 하는 repository가 최신 상태가 아니면 Working tree has modifications. Cannot add. 오류가 발생하기 때문에 최신화 해둘 것. 로컬에 프로젝트가 복사된 것이 확인되었다면 그대로 git push
1. json.dumps() import json my_dict = {"name": "John", "age": 30} my_str = json.dumps(my_dict) print(my_str) # '{"name": "John", "age": 30}' 2. str my_dict = {"name": "John", "age": 30} my_str = str(my_dict) print(my_str) # "{'name': 'John', 'age': 30}" 3. pprint().pformat() import pprint my_dict = {"name": "John", "age": 30} my_str = pprint.pformat(my_dict) print(my_str) # 출력 결과: # {'age': 30, ..
def df_to_excel(self, dtos): try: excel = os.path.join('filename.xlsx') if os.path.isfile(excel): with pd.ExcelWriter(bid_notice_excel, engine="openpyxl", mode="a", if_sheet_exists="replace") as writer: pd.DataFrame.from_dict(dtos).to_excel(writer, sheet_name='sheet_name2', index=False) else: with pd.ExcelWriter(excel, engine="openpyxl") as writer: pd.DataFrame.from_dict(dtos).to_excel(writer, s..
import numpy as np # 입력 배열 생성 arr = np.array([1, 2, 3, 4, 5]) # 특정 값 더하기 add_value = 10 arr = arr + add_value # 결과 출력 print(arr) 모든 값에 10씩 더해진다.
import os filename = 'file.txt' # 생성하려는 파일명 counter = 0 # 파일명 뒤에 붙일 숫자 초기값 while True: if not os.path.exists(filename): # 파일명이 이미 존재하지 않는 경우 break # 반복문 종료 counter += 1 # 파일명 뒤에 붙일 숫자 증가 filename = f'file_{counter}.txt' # 파일명에 숫자를 붙여서 새로운 파일명 생성 with open(filename, 'w') as file: file.write('Hello, world!') # 파일 생성 후 내용 쓰기 zfill 함수를 사용한다면 더욱 깔끔한 넘버링이 가능하니 취향껏 사용해도 좋음
현재 로컬 버전과 원격 버전이 동일한 경우 git pull을 사용하면 'Already up to date' 라는 메시지가 나오게 된다. 그 상태에서 코드를 약간 수정하다가 다시 원격에 있는 상태를 그대로 가져오고 싶었던 적이 있었을 때, 아래와 같은 명령어를 사용했다. # 로컬 변경 내용을 stash에 저장 $ git stash # 원격 저장소의 최신 변경 내용 가져오기 $ git pull # stash에 저장한 변경 내용 복원 $ git stash pop stash에 임시로 내용을 저장한 후, git pull 명령어로 원격의 내용을 불러온 것.
# 반복문 안에서 여러 개의 배열을 생성하는 예시 for i in range(3): # 각 배열에 다른 이름을 부여하여 생성 locals()[f'array_{i}'] = [] # locals() 함수를 사용하여 현재 로컬 스코프에 변수를 동적으로 생성 # 배열에 원하는 데이터를 추가 locals()[f'array_{i}'].append(i) # 생성된 배열 확인 print(array_0) # 출력: [0] print(array_1) # 출력: [1] print(array_2) # 출력: [2] locals() 함수를 사용하여 현재 로컬 스코프에 변수를 동적으로 생성할 수 있다. 이렇게 생성된 배열은 현재 스코프에서만 사용이 가능하다.