
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- vscode venv 설치
- pywinauto 윈도우
- 날짜 정규식
- 파이썬 가상환경 설치
- pywinauto
- pycdas.exe
- Python
- 파이썬 네이버 로그인
- 네이버 로그인 하기
- UiPath
- 커머스API
- Element is not clickable at point
- 네이버부동산크롤링
- venv 설치
- Uipath 기초
- pywinauto 윈도우제어
- 네이버커머스API
- 네이버 로그인 캡챠해결
- 파이썬 환경설정
- 네이버 로그인 영수증 해결
- 파이썬네이버부동산
- selenium
- Selenium 셀렉터잡기
- Uipath 설치방법
- 가상환경설치
- 파이썬 가상환경 설치방법
- uipath 입문
- 왕초보 파이썬 실행
- 네이버매물크롤링
- pycdc.exe
- Today
- Total
콘솔워크
[Python dataframe] Union and Union ALL 본문
pandas의 두 데이터 프레임을 모두 결합하는 것은 concat () 함수를 사용하여 간단한 원형 교차로 방식으로 수행됩니다. pandas의 합집합 기능은 합집합과 비슷하지만 중복을 제거합니다. 팬더의 합집합은 concat () 및 drop_duplicates () 함수를 사용하여 수행됩니다. 예를 들어 설명하면 명확해질 것입니다. Pandas dataframe python에서 Union과 Union을 모두 사용하는 방법을 살펴 보겠습니다.Pandas 데이터 프레임 Python에서 모두 통합 및 통합 :
concat () 함수를 사용하여 팬더의 두 데이터 프레임을 모두 쉽게 통합 할 수 있습니다. 예를 들어 보겠습니다. 먼저 두 개의 데이터 프레임을 만듭니다.
df1은
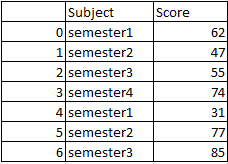
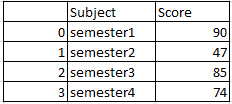
df2는
import pandas as pd
import numpy as np
#Create a DataFrame
df1 = {
'Subject':['semester1','semester2','semester3','semester4','semester1',
'semester2','semester3'],
'Score':[62,47,55,74,31,77,85]}
df2 = {
'Subject':['semester1','semester2','semester3','semester4'],
'Score':[90,47,85,74]}
df1 = pd.DataFrame(df1,columns=['Subject','Score'])
df2 = pd.DataFrame(df2,columns=['Subject','Score'])
Pandas의 모든 데이터 프레임을 통합합니다.
UNION ALL
pandas의 concat () 함수는 두 데이터 프레임의 합집합을 만듭니다.
두 데이터 프레임 df1 및 df2 모두를 결합하여 중복으로 생성됩니다. 따라서 결과 데이터 프레임은
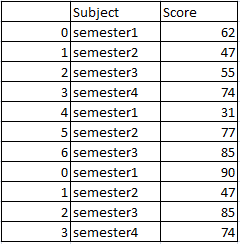
# Union all in pandas
f_union_all= pd.concat([df1, df2])
df_union_allPandas의 모든 데이터 프레임을 통합하고 다시 색인화합니다.
pandas의 concat () 함수는 ignore_index = True로 두 데이터 프레임의 결합을 생성합니다.
두 개의 데이터 프레임 df1과 df2를 모두 합집합하면 중복이 생성되고 인덱스가 변경됩니다. 따라서 결과 데이터 프레임은
# Union all with reindex in pandas
df_union_all= pd.concat([df1, df2],ignore_index=True)
df_union_all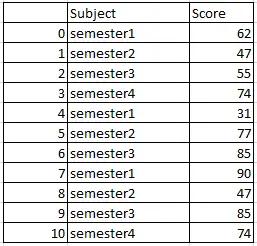
Pandas의 데이터 프레임 통합 :
노동 조합
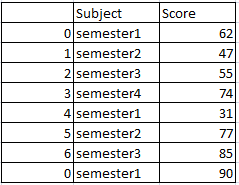
pandas의 concat () 함수는 drop_duplicates ()와 함께 중복없이 두 데이터 프레임의 결합을 생성합니다. 이는 데이터 프레임의 결합 일뿐입니다.
# union in pandas
df_union= pd.concat([df1, df2]).drop_duplicates()
print(df_union)두 데이터 프레임 df1 및 df2의 합집합은 중복을 제거하여 생성됩니다. 따라서 결과 데이터 프레임은
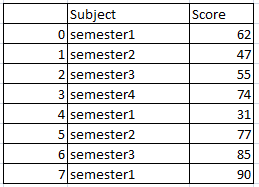
재색 인화를 통한 Pandas의 데이터 프레임 통합 :
pandas의 concat () 함수는 drop_duplicates ()와 함께 중복없이 두 데이터 프레임의 결합을 생성합니다. 이는 데이터 프레임의 결합 일뿐입니다. 또한 ignore_index = True로 데이터 프레임을 다시 색인화합니다.
# union in pandas
df_union= pd.concat([df1, df2],ignore_index=True).drop_duplicates()
df_union
중복을 제거하여 두 데이터 프레임 df1과 df2의 합집합이 생성되고 인덱스도 변경됩니다. 따라서 결과 데이터 프레임은
'프로그래밍 > python' 카테고리의 다른 글
| [나도코딩 웹스크래핑] 정리 (0) | 2021.01.17 |
|---|---|
| [나도코딩 웹스크래핑] Chrome headless 최종소스 (0) | 2021.01.17 |
| [Python dataframe] 값이 없는 데이터 filtering notnull (0) | 2021.01.12 |
| [Python dataframe] 특정컬럼의 특정 값 변경 (replace) (0) | 2021.01.12 |
| [나도코딩 웹스크래핑] User-Agent (0) | 2021.01.12 |
